PyEarthTool BARRA2 tutorial#
This notebook will be used to load, transform and plot BARRA2 data with PyEarthTools (PET). The aim is to showcase the implementation of BARRA2 in PET and how to match BARRA-RE2 to ERA5. At the end of this notebook we will have:
loaded BARRA-R2 and ERA5 data,
combined hourly instantaneous and hourly averaged variables into a single dataset,
regridded ERA5 to BARRA-R2 resolution,
plotted BARRA-R2 time means on a map and compared them against ERA5,
plotted and compared BARRA-R2 and ERA5 in histograms.
[1]:
import matplotlib.pyplot as plt
import numpy as np
import xarray as xr
import dask.distributed
import cartopy.crs as ccrs
# Load PET specific modules and NCI settings
import pyearthtools
import pyearthtools.data as petdata
import pyearthtools.pipeline as petpipe
import site_archive_nci
import warnings
warnings.filterwarnings('ignore')
Start a dask client to help with faster processing.
[2]:
client = dask.distributed.Client(n_workers = 25, threads_per_worker=1)
client
[2]:
Client
Client-89e77046-a593-11f0-81db-000003a8fe80
| Connection method: Cluster object | Cluster type: distributed.LocalCluster |
| Dashboard: /proxy/8787/status |
Cluster Info
LocalCluster
33eea306
| Dashboard: /proxy/8787/status | Workers: 25 |
| Total threads: 25 | Total memory: 251.19 GiB |
| Status: running | Using processes: True |
Scheduler Info
Scheduler
Scheduler-be5ebb43-e69d-4bac-97b4-35afd34a6a06
| Comm: tcp://127.0.0.1:42963 | Workers: 0 |
| Dashboard: /proxy/8787/status | Total threads: 0 |
| Started: Just now | Total memory: 0 B |
Workers
Worker: 0
| Comm: tcp://127.0.0.1:44843 | Total threads: 1 |
| Dashboard: /proxy/35559/status | Memory: 10.05 GiB |
| Nanny: tcp://127.0.0.1:33803 | |
| Local directory: /jobfs/152045559.gadi-pbs/dask-scratch-space/worker-odgu1acn | |
Worker: 1
| Comm: tcp://127.0.0.1:34549 | Total threads: 1 |
| Dashboard: /proxy/39389/status | Memory: 10.05 GiB |
| Nanny: tcp://127.0.0.1:44125 | |
| Local directory: /jobfs/152045559.gadi-pbs/dask-scratch-space/worker-nqrj594t | |
Worker: 2
| Comm: tcp://127.0.0.1:38999 | Total threads: 1 |
| Dashboard: /proxy/34353/status | Memory: 10.05 GiB |
| Nanny: tcp://127.0.0.1:45397 | |
| Local directory: /jobfs/152045559.gadi-pbs/dask-scratch-space/worker-1zs2ely5 | |
Worker: 3
| Comm: tcp://127.0.0.1:42633 | Total threads: 1 |
| Dashboard: /proxy/46709/status | Memory: 10.05 GiB |
| Nanny: tcp://127.0.0.1:36173 | |
| Local directory: /jobfs/152045559.gadi-pbs/dask-scratch-space/worker-no3x0wso | |
Worker: 4
| Comm: tcp://127.0.0.1:42551 | Total threads: 1 |
| Dashboard: /proxy/39691/status | Memory: 10.05 GiB |
| Nanny: tcp://127.0.0.1:46761 | |
| Local directory: /jobfs/152045559.gadi-pbs/dask-scratch-space/worker-t_35aqmr | |
Worker: 5
| Comm: tcp://127.0.0.1:42427 | Total threads: 1 |
| Dashboard: /proxy/40341/status | Memory: 10.05 GiB |
| Nanny: tcp://127.0.0.1:44639 | |
| Local directory: /jobfs/152045559.gadi-pbs/dask-scratch-space/worker-38p2hh67 | |
Worker: 6
| Comm: tcp://127.0.0.1:44645 | Total threads: 1 |
| Dashboard: /proxy/36859/status | Memory: 10.05 GiB |
| Nanny: tcp://127.0.0.1:43709 | |
| Local directory: /jobfs/152045559.gadi-pbs/dask-scratch-space/worker-1sez897f | |
Worker: 7
| Comm: tcp://127.0.0.1:42273 | Total threads: 1 |
| Dashboard: /proxy/37079/status | Memory: 10.05 GiB |
| Nanny: tcp://127.0.0.1:43419 | |
| Local directory: /jobfs/152045559.gadi-pbs/dask-scratch-space/worker-b22hsi5r | |
Worker: 8
| Comm: tcp://127.0.0.1:35959 | Total threads: 1 |
| Dashboard: /proxy/33479/status | Memory: 10.05 GiB |
| Nanny: tcp://127.0.0.1:35565 | |
| Local directory: /jobfs/152045559.gadi-pbs/dask-scratch-space/worker-4ei38jyc | |
Worker: 9
| Comm: tcp://127.0.0.1:46665 | Total threads: 1 |
| Dashboard: /proxy/34155/status | Memory: 10.05 GiB |
| Nanny: tcp://127.0.0.1:43603 | |
| Local directory: /jobfs/152045559.gadi-pbs/dask-scratch-space/worker-dny2qgap | |
Worker: 10
| Comm: tcp://127.0.0.1:37857 | Total threads: 1 |
| Dashboard: /proxy/44393/status | Memory: 10.05 GiB |
| Nanny: tcp://127.0.0.1:42741 | |
| Local directory: /jobfs/152045559.gadi-pbs/dask-scratch-space/worker-v7atgo46 | |
Worker: 11
| Comm: tcp://127.0.0.1:42227 | Total threads: 1 |
| Dashboard: /proxy/36147/status | Memory: 10.05 GiB |
| Nanny: tcp://127.0.0.1:33437 | |
| Local directory: /jobfs/152045559.gadi-pbs/dask-scratch-space/worker-khcs_2kq | |
Worker: 12
| Comm: tcp://127.0.0.1:39053 | Total threads: 1 |
| Dashboard: /proxy/33501/status | Memory: 10.05 GiB |
| Nanny: tcp://127.0.0.1:43327 | |
| Local directory: /jobfs/152045559.gadi-pbs/dask-scratch-space/worker-9myrqmun | |
Worker: 13
| Comm: tcp://127.0.0.1:45131 | Total threads: 1 |
| Dashboard: /proxy/34351/status | Memory: 10.05 GiB |
| Nanny: tcp://127.0.0.1:37587 | |
| Local directory: /jobfs/152045559.gadi-pbs/dask-scratch-space/worker-l2z21qa9 | |
Worker: 14
| Comm: tcp://127.0.0.1:36693 | Total threads: 1 |
| Dashboard: /proxy/40609/status | Memory: 10.05 GiB |
| Nanny: tcp://127.0.0.1:46693 | |
| Local directory: /jobfs/152045559.gadi-pbs/dask-scratch-space/worker-p6jvzsu4 | |
Worker: 15
| Comm: tcp://127.0.0.1:41473 | Total threads: 1 |
| Dashboard: /proxy/41251/status | Memory: 10.05 GiB |
| Nanny: tcp://127.0.0.1:37351 | |
| Local directory: /jobfs/152045559.gadi-pbs/dask-scratch-space/worker-3h1jw9_f | |
Worker: 16
| Comm: tcp://127.0.0.1:45463 | Total threads: 1 |
| Dashboard: /proxy/36907/status | Memory: 10.05 GiB |
| Nanny: tcp://127.0.0.1:46487 | |
| Local directory: /jobfs/152045559.gadi-pbs/dask-scratch-space/worker-0gpu5gv4 | |
Worker: 17
| Comm: tcp://127.0.0.1:46483 | Total threads: 1 |
| Dashboard: /proxy/33461/status | Memory: 10.05 GiB |
| Nanny: tcp://127.0.0.1:41559 | |
| Local directory: /jobfs/152045559.gadi-pbs/dask-scratch-space/worker-8z75zh5b | |
Worker: 18
| Comm: tcp://127.0.0.1:35801 | Total threads: 1 |
| Dashboard: /proxy/38783/status | Memory: 10.05 GiB |
| Nanny: tcp://127.0.0.1:36251 | |
| Local directory: /jobfs/152045559.gadi-pbs/dask-scratch-space/worker-w2d9ulb8 | |
Worker: 19
| Comm: tcp://127.0.0.1:34677 | Total threads: 1 |
| Dashboard: /proxy/44149/status | Memory: 10.05 GiB |
| Nanny: tcp://127.0.0.1:37491 | |
| Local directory: /jobfs/152045559.gadi-pbs/dask-scratch-space/worker-hucmp28q | |
Worker: 20
| Comm: tcp://127.0.0.1:43941 | Total threads: 1 |
| Dashboard: /proxy/34117/status | Memory: 10.05 GiB |
| Nanny: tcp://127.0.0.1:35605 | |
| Local directory: /jobfs/152045559.gadi-pbs/dask-scratch-space/worker-izin86im | |
Worker: 21
| Comm: tcp://127.0.0.1:38417 | Total threads: 1 |
| Dashboard: /proxy/45961/status | Memory: 10.05 GiB |
| Nanny: tcp://127.0.0.1:43567 | |
| Local directory: /jobfs/152045559.gadi-pbs/dask-scratch-space/worker-eu_oh5oj | |
Worker: 22
| Comm: tcp://127.0.0.1:37443 | Total threads: 1 |
| Dashboard: /proxy/37777/status | Memory: 10.05 GiB |
| Nanny: tcp://127.0.0.1:42133 | |
| Local directory: /jobfs/152045559.gadi-pbs/dask-scratch-space/worker-_y1ywsdz | |
Worker: 23
| Comm: tcp://127.0.0.1:38651 | Total threads: 1 |
| Dashboard: /proxy/37557/status | Memory: 10.05 GiB |
| Nanny: tcp://127.0.0.1:37633 | |
| Local directory: /jobfs/152045559.gadi-pbs/dask-scratch-space/worker-cw616rvj | |
Worker: 24
| Comm: tcp://127.0.0.1:33241 | Total threads: 1 |
| Dashboard: /proxy/43307/status | Memory: 10.05 GiB |
| Nanny: tcp://127.0.0.1:45343 | |
| Local directory: /jobfs/152045559.gadi-pbs/dask-scratch-space/worker-w5fo_hqm | |
2025-10-10 15:50:06,524 - distributed.scheduler - WARNING - Detected different `run_spec` for key ('where-getitem-44ee83ba71035d1c16fab2ee0d26a64d', 1, 0, 0, 0) between two consecutive calls to `update_graph`. This can cause failures and deadlocks down the line. Please ensure unique key names. If you are using a standard dask collections, consider releasing all the data before resubmitting another computation. More details and help can be found at https://github.com/dask/dask/issues/9888.
Debugging information
---------------------
old task state: released
old run_spec: <Task ('where-getitem-44ee83ba71035d1c16fab2ee0d26a64d', 1, 0, 0, 0) _execute_subgraph(...)>
new run_spec: <Task ('where-getitem-44ee83ba71035d1c16fab2ee0d26a64d', 1, 0, 0, 0) _execute_subgraph(...)>
old dependencies: {('array-1defe82f28400b0bc9287e918e13ce36', 0, 0, 0, 0), ('eq-76cf084d4035f655357dfe14cabd9f85', 0, 0, 0, 0), ('array-4e137fb0017e1888354c77ed7340d853', 1, 0, 0, 0), ('array-4bdd9cbd06fcdea45fac05402c2306e7', 0, 0, 0, 0), ('getitem-ed3cf0281595955a931c0b6465de0b04', 1, 0, 0, 0)}
new dependencies: frozenset({('array-35f70bfa5a481be3e5b938bb77e43d01', 0, 0, 0, 0), ('array-4e137fb0017e1888354c77ed7340d853', 1, 0, 0, 0), ('array-1defe82f28400b0bc9287e918e13ce36', 0, 0, 0, 0), ('array-4bdd9cbd06fcdea45fac05402c2306e7', 0, 0, 0, 0), ('getitem-ed3cf0281595955a931c0b6465de0b04', 1, 0, 0, 0)})
2025-10-10 15:51:58,920 - distributed.scheduler - WARNING - Detected different `run_spec` for key ('where-getitem-d680230fa49040d5f7068cba47d738e0', 0, 1, 1, 0) between two consecutive calls to `update_graph`. This can cause failures and deadlocks down the line. Please ensure unique key names. If you are using a standard dask collections, consider releasing all the data before resubmitting another computation. More details and help can be found at https://github.com/dask/dask/issues/9888.
Debugging information
---------------------
old task state: released
old run_spec: <Task ('where-getitem-d680230fa49040d5f7068cba47d738e0', 0, 1, 1, 0) _execute_subgraph(...)>
new run_spec: <Task ('where-getitem-d680230fa49040d5f7068cba47d738e0', 0, 1, 1, 0) _execute_subgraph(...)>
old dependencies: {('logical_not-60e08ab5f8a978e615d0c099e4bf6b6f', 0, 1, 1, 0), ('getitem-e4dec4ee18bc87acab4d98969867db76', 0, 1, 1, 0)}
new dependencies: frozenset({('array-a34cae560d34f17b3bf8740bdb064830', 0, 0, 1, 0), ('array-35f70bfa5a481be3e5b938bb77e43d01', 0, 1, 0, 0), ('getitem-e4dec4ee18bc87acab4d98969867db76', 0, 1, 1, 0), ('array-bd5ddc5ddd2584dc1bec4284880bc7f1', 0, 0, 0, 0), ('array-95d73296fca06939246e04953780ddd0', 0, 0, 0, 0)})
2025-10-10 15:53:58,380 - distributed.scheduler - WARNING - Detected different `run_spec` for key ('where-getitem-9c7121758b2db8b0866235e4bec62291', 1, 3, 1, 1) between two consecutive calls to `update_graph`. This can cause failures and deadlocks down the line. Please ensure unique key names. If you are using a standard dask collections, consider releasing all the data before resubmitting another computation. More details and help can be found at https://github.com/dask/dask/issues/9888.
Debugging information
---------------------
old task state: released
old run_spec: <Task ('where-getitem-9c7121758b2db8b0866235e4bec62291', 1, 3, 1, 1) _execute_subgraph(...)>
new run_spec: <Task ('where-getitem-9c7121758b2db8b0866235e4bec62291', 1, 3, 1, 1) _execute_subgraph(...)>
old dependencies: {('logical_not-60e08ab5f8a978e615d0c099e4bf6b6f', 1, 3, 1, 1), ('getitem-be658b74b22bec884922bb7aec824d62', 1, 3, 1, 1)}
new dependencies: frozenset({('array-35f70bfa5a481be3e5b938bb77e43d01', 0, 3, 0, 0), ('array-a34cae560d34f17b3bf8740bdb064830', 0, 0, 1, 0), ('getitem-be658b74b22bec884922bb7aec824d62', 1, 3, 1, 1), ('array-95d73296fca06939246e04953780ddd0', 0, 0, 0, 1), ('array-bd5ddc5ddd2584dc1bec4284880bc7f1', 1, 0, 0, 0)})
2025-10-10 16:02:53,077 - distributed.scheduler - WARNING - Detected different `run_spec` for key ('truediv-08dee36fef287260c4b84176e39ea2b6', 2, 1, 0) between two consecutive calls to `update_graph`. This can cause failures and deadlocks down the line. Please ensure unique key names. If you are using a standard dask collections, consider releasing all the data before resubmitting another computation. More details and help can be found at https://github.com/dask/dask/issues/9888.
Debugging information
---------------------
old task state: released
old run_spec: <Task ('truediv-08dee36fef287260c4b84176e39ea2b6', 2, 1, 0) _execute_subgraph(...)>
new run_spec: Alias(('truediv-08dee36fef287260c4b84176e39ea2b6', 2, 1, 0)->('interpnd-interpnd_0-truediv-08dee36fef287260c4b84176e39ea2b6', 2, 1, 0))
old dependencies: {('interpnd_0-33548c492abf04cc579f88e56b424370', 2, 1, 0)}
new dependencies: frozenset({('interpnd-interpnd_0-truediv-08dee36fef287260c4b84176e39ea2b6', 2, 1, 0)})
2025-10-10 16:06:28,287 - distributed.scheduler - WARNING - Detected different `run_spec` for key ('truediv-c1cd43cd7f6b926fa035f646d6981e7d', 7, 1, 0) between two consecutive calls to `update_graph`. This can cause failures and deadlocks down the line. Please ensure unique key names. If you are using a standard dask collections, consider releasing all the data before resubmitting another computation. More details and help can be found at https://github.com/dask/dask/issues/9888.
Debugging information
---------------------
old task state: released
old run_spec: <Task ('truediv-c1cd43cd7f6b926fa035f646d6981e7d', 7, 1, 0) _execute_subgraph(...)>
new run_spec: Alias(('truediv-c1cd43cd7f6b926fa035f646d6981e7d', 7, 1, 0)->('interpnd-interpnd_0-truediv-c1cd43cd7f6b926fa035f646d6981e7d', 7, 1, 0))
old dependencies: {('interpnd_0-dfef60df2f71da97fae6410233a62307', 7, 1, 0)}
new dependencies: frozenset({('interpnd-interpnd_0-truediv-c1cd43cd7f6b926fa035f646d6981e7d', 7, 1, 0)})
Load some BARRA-R2 and ERA5 data#
This builds an accessor, called barra2 and era5, that can be indexed by time, filtered according to the specified parameters. Here we want to look at a list of variables.
For BARRA2, we need to create two variable lists, and two accessors, because some fields are instantaneous (e.g., tas) and are valid at full hours (e.g., 01:00), while others represent hourly averages (e.g., pr) and have a valid time at half hours (e.g., 00:30).
[3]:
varlist_hourly_instant = [
'tas', # surface temperature
'ta500', # temperature at 500hPa
'uas', # 10m u-winds
'ua500', # u-wind at 500hPa
'vas', # 10m v-winds
'va500', # v-winds at 500hPa
'omega500', # pressure velocity at 500hPa
'hus500', # specific humidity at 500hPa
'psl', # mean sea level pressure
'prw', # water vapour path,
'zg500', # geopotential at 500hPa
]
varlist_hourly_averaged = [
'pr', # hourly average precipitation
'clt', # hourly average cloud cover
'rsdt', # hourly average TOA Incident Shortwave Radiation
'rsds', # hourly average shortwave down surface
'rsut', # hourly average TOA outgoing shortwave
'rlus', # hourly averaged longwave up surface
'rlds', # hourly average longwave down surface
'rlut', # hourly average TOA outgoing longwave
]
# The full varlist is
varlist = varlist_hourly_instant + varlist_hourly_averaged
Now create an accessor for BARRA-R2.
[4]:
barra2_hinstant = petdata.archive.BARRA_V2(varlist_hourly_instant, domain_id='AUS-11', frequency='1hr')
barra2_haveraged = petdata.archive.BARRA_V2(varlist_hourly_averaged, domain_id='AUS-11', frequency='1hr')
To open the same variables with ERA5, we need a mapping from the names in BARRA2 to ERA5
[5]:
barra2era_map = {
'tas': '2t',
'ta500': 't',
'uas': 'u10n',
'ua500': 'u',
'vas': 'v10n',
'va500': 'v',
'omega500': 'w',
'hus500': 'q',
'ps': 'sp',
'psl': 'msl',
'prw': 'tcw',
'pr': 'tp',
'clt': 'tcc',
'zg500': 'z',
# following https://www.ecmwf.int/sites/default/files/elibrary/2015/18490-radiation-quantities-ecmwf-model-and-mars.pdf
'rsdt': 'tisr', # J m-2
'rsds': 'ssrd', # J m-2
'rsut': 'tsr', # tisr - tsr, J m-2
'rlus': 'str', # strd - str, J m-2
'rlds': 'strd', # J m-2
'rlut': 'ttr', # J m-2
}
Now create an accessor for ERA5.
[6]:
era5 = petdata.archive.ERA5([barra2era_map[key] for key in varlist], product='reanalysis')
Now that we have our accessors, lets extract a years worth of data and compare ERA5 and BARRA2
[7]:
ds_barra2_hinstant = barra2_hinstant.series('2000-01-01', '2000-01-31T23', interval = (1, 'hour'))
ds_barra2_haveraged = barra2_haveraged.series('2000-01-01', '2000-01-31T23', interval = (1, 'hour'))
# # Some BARRA2 fields have a single length heigh dimension. We do not want this.
try:
ds_barra2_hinstant = ds_barra2_hinstant.mean('height')
ds_barra2_haveraged = ds_barra2_haveraged.mean('height')
except:
pass
Now that we have both instantaneous and hourly averaged fields, we resample the averaged values to hourly values valid at the same time as the instantaneous fields.
Then we combine them in one dataset.
Because the first time step in the averaged fields is 00:30, when interpolated the new first time step (i.e., 00:00) will be NaN. We drop the first time step after resampling to avoid this.
[8]:
ds_barra2_haveraged = ds_barra2_haveraged.resample(dict(time="1H")).interpolate('linear')
ds_barra2 = xr.merge([ds_barra2_hinstant, ds_barra2_haveraged])
ds_barra2 = ds_barra2.drop_isel(time=0)
ds_barra2 = ds_barra2.squeeze()
# Rename some variables for ease later
# When we want to use more pressure levels this might have to be dealt
# with in a smarter way...
ds_barra2 = ds_barra2.rename({
'ta': 'ta500',
'ua': 'ua500',
'va': 'va500',
'omega': 'omega500',
'hus': 'hus500',
'zg': 'zg500',
})
ds_barra2
[8]:
<xarray.Dataset> Size: 79GB
Dimensions: (time: 742, longitude: 1082, latitude: 646, bnds: 2)
Coordinates:
* time (time) datetime64[ns] 6kB 2000-01-01T01:00:00 ... 2000-01-31T2...
* longitude (longitude) float64 9kB 88.48 88.59 88.7 ... 207.2 207.3 207.4
* latitude (latitude) float64 5kB -57.97 -57.86 -57.75 ... 12.76 12.87 12.98
crs int32 4B 0
pressure float64 8B 500.0
* bnds (bnds) float64 16B 0.0 1.0
Data variables: (12/19)
uas (time, latitude, longitude) float64 4GB dask.array<chunksize=(61, 392, 668), meta=np.ndarray>
hus500 (time, latitude, longitude) float64 4GB dask.array<chunksize=(61, 396, 660), meta=np.ndarray>
omega500 (time, latitude, longitude) float64 4GB dask.array<chunksize=(61, 392, 668), meta=np.ndarray>
va500 (time, latitude, longitude) float64 4GB dask.array<chunksize=(61, 396, 660), meta=np.ndarray>
prw (time, latitude, longitude) float64 4GB dask.array<chunksize=(61, 396, 660), meta=np.ndarray>
ta500 (time, latitude, longitude) float64 4GB dask.array<chunksize=(61, 396, 660), meta=np.ndarray>
... ...
rlut (time, latitude, longitude) float64 4GB dask.array<chunksize=(742, 98, 167), meta=np.ndarray>
clt (time, latitude, longitude) float64 4GB dask.array<chunksize=(742, 99, 165), meta=np.ndarray>
rlds (time, latitude, longitude) float64 4GB dask.array<chunksize=(742, 99, 165), meta=np.ndarray>
pr (time, latitude, longitude) float64 4GB dask.array<chunksize=(742, 97, 168), meta=np.ndarray>
rsut (time, latitude, longitude) float64 4GB dask.array<chunksize=(742, 99, 165), meta=np.ndarray>
rlus (time, latitude, longitude) float64 4GB dask.array<chunksize=(742, 98, 167), meta=np.ndarray>
Attributes: (12/53)
axiom_version: 0.1.0
axiom_schemas_version: 0.1.0
axiom_schema: cordex-1H.json
productive_version: f5a7b55
variable_version: v20231001
Conventions: CF-1.10, ACDD-1.3
... ...
geospatial_lat_min: -57.97
geospatial_lat_max: 12.98
geospatial_lat_units: degrees_north
geospatial_lon_min: 88.48
geospatial_lon_max: 207.39
geospatial_lon_units: degrees_eastNow that BARRA2 is opened, we work on ERA5. This is easier, as all fields are on the full hour (e.g., 01:00)
[9]:
ds_era5 = era5.series('2000-01-01', '2000-01-31T23', interval = (1, 'hour'))
# We also drop the first time step in the ERA5 dataset to match BARRA2
ds_era5 = ds_era5.drop_isel(time=0)
# Some variables have pressure levels in them.
# For now we only want pressure level 500hPa, later this might need to be refined
ds_era5 = ds_era5.sel(level=500)
ds_era5
[9]:
<xarray.Dataset> Size: 114GB
Dimensions: (time: 742, latitude: 721, longitude: 1440)
Coordinates:
* longitude (longitude) float32 6kB -180.0 -179.8 -179.5 ... 179.5 179.8
* latitude (latitude) float32 3kB 90.0 89.75 89.5 ... -89.5 -89.75 -90.0
* time (time) datetime64[ns] 6kB 2000-01-01T01:00:00 ... 2000-01-31T2...
level int32 4B 500
Data variables: (12/19)
ssrd (time, latitude, longitude) float64 6GB dask.array<chunksize=(185, 182, 360), meta=np.ndarray>
tcw (time, latitude, longitude) float64 6GB dask.array<chunksize=(185, 182, 360), meta=np.ndarray>
msl (time, latitude, longitude) float64 6GB dask.array<chunksize=(185, 182, 360), meta=np.ndarray>
u10n (time, latitude, longitude) float64 6GB dask.array<chunksize=(185, 182, 360), meta=np.ndarray>
strd (time, latitude, longitude) float64 6GB dask.array<chunksize=(185, 182, 360), meta=np.ndarray>
ttr (time, latitude, longitude) float64 6GB dask.array<chunksize=(185, 182, 360), meta=np.ndarray>
... ...
tsr (time, latitude, longitude) float64 6GB dask.array<chunksize=(185, 182, 360), meta=np.ndarray>
tcc (time, latitude, longitude) float64 6GB dask.array<chunksize=(185, 182, 360), meta=np.ndarray>
t (time, latitude, longitude) float64 6GB dask.array<chunksize=(3, 405, 900), meta=np.ndarray>
w (time, latitude, longitude) float64 6GB dask.array<chunksize=(3, 405, 900), meta=np.ndarray>
u (time, latitude, longitude) float64 6GB dask.array<chunksize=(3, 405, 900), meta=np.ndarray>
tp (time, latitude, longitude) float64 6GB dask.array<chunksize=(185, 182, 360), meta=np.ndarray>
Attributes:
Conventions: CF-1.6
license: Licence to use Copernicus Products: https://apps.ecmwf.int/...
summary: ERA5 is the fifth generation ECMWF atmospheric reanalysis o...ERA5 and BARRA-R2 have different horizontal resolutions. Lets interpolate ERA5 onto the BARRA-R2 grid. We define a reference grid that we interpolate ERA5 to. ERA5 also has longitudes from -180 to 180, while BARRA2 goes from 0 to 360. We need to updated ERA5 lons to match BARRA2.
[10]:
# Define the reference grid
refgrid = ds_barra2.isel(time=0)[varlist[0]].squeeze()
# Sort lons like BARRA2
ds_era5 = ds_era5.assign_coords(longitude=(ds_era5['longitude'] % 360))
ds_era5 = ds_era5.sortby(ds_era5["longitude"])
# Interpolate like BARRA2
ds_era5_regrid = ds_era5.interp_like(refgrid)
ds_era5_regrid
[10]:
<xarray.Dataset> Size: 77GB
Dimensions: (time: 742, latitude: 646, longitude: 1082)
Coordinates:
* time (time) datetime64[ns] 6kB 2000-01-01T01:00:00 ... 2000-01-31T2...
level int32 4B 500
* latitude (latitude) float64 5kB -57.97 -57.86 -57.75 ... 12.76 12.87 12.98
* longitude (longitude) float64 9kB 88.48 88.59 88.7 ... 207.2 207.3 207.4
Data variables: (12/19)
ssrd (time, latitude, longitude) float64 4GB dask.array<chunksize=(47, 323, 1082), meta=np.ndarray>
tcw (time, latitude, longitude) float64 4GB dask.array<chunksize=(47, 323, 1082), meta=np.ndarray>
msl (time, latitude, longitude) float64 4GB dask.array<chunksize=(47, 323, 1082), meta=np.ndarray>
u10n (time, latitude, longitude) float64 4GB dask.array<chunksize=(47, 323, 1082), meta=np.ndarray>
strd (time, latitude, longitude) float64 4GB dask.array<chunksize=(47, 323, 1082), meta=np.ndarray>
ttr (time, latitude, longitude) float64 4GB dask.array<chunksize=(47, 323, 1082), meta=np.ndarray>
... ...
tsr (time, latitude, longitude) float64 4GB dask.array<chunksize=(47, 323, 1082), meta=np.ndarray>
tcc (time, latitude, longitude) float64 4GB dask.array<chunksize=(47, 323, 1082), meta=np.ndarray>
t (time, latitude, longitude) float64 4GB dask.array<chunksize=(3, 646, 1082), meta=np.ndarray>
w (time, latitude, longitude) float64 4GB dask.array<chunksize=(3, 646, 1082), meta=np.ndarray>
u (time, latitude, longitude) float64 4GB dask.array<chunksize=(3, 646, 1082), meta=np.ndarray>
tp (time, latitude, longitude) float64 4GB dask.array<chunksize=(47, 323, 1082), meta=np.ndarray>
Attributes:
Conventions: CF-1.6
license: Licence to use Copernicus Products: https://apps.ecmwf.int/...
summary: ERA5 is the fifth generation ECMWF atmospheric reanalysis o...Transformations#
The units for some variables between BARRA2 and ERA5 do not match! We need to do some conversions.
[11]:
# Convert total cloud cover to percent
ds_era5_regrid['tcc'] = ds_era5_regrid['tcc'] * 100.
# Convert metres of precipitation to kg m-2 s-1
ds_era5_regrid['tp'] = ds_era5_regrid['tp'] * 1000 / 3600
# Convert geopotential
ds_era5_regrid['z'] = ds_era5_regrid['z'] / 9.81 # rsdt
# Convert J m-2 to W m-2
ds_era5_regrid['tisr'] = ds_era5_regrid['tisr'] / 3600 # rsdt
ds_era5_regrid['ssrd'] = ds_era5_regrid['ssrd'] / 3600 # rsds
ds_era5_regrid['tsr'] = ds_era5_regrid['tsr'] / 3600 # rsut
ds_era5_regrid['str'] = ds_era5_regrid['str'] / 3600 # rlus
ds_era5_regrid['strd'] = ds_era5_regrid['strd'] / 3600 # rlds
ds_era5_regrid['ttr'] = ds_era5_regrid['ttr'] / (-3600) # rlut
# Use net radiation fields to get some missing components
ds_era5_regrid['tsr'] = ds_era5_regrid['tisr'] - ds_era5_regrid['tsr']
ds_era5_regrid['str'] = ds_era5_regrid['strd'] - ds_era5_regrid['str']
Now that we have:
resampled, averaged values to the same valid time as instantaneous values,
ommitted the first time step, which is NaN after resampling,
regridded, ERA5 to the BARRA-R2 grid,
converted the ERA5 units to match the ones in BARRA-R2 for each variable,
we are ready to plot and compare the monthly mean values.
We also added a bias plot, showing the difference between BARRA-R2 and ERA5, as well as a spatial correlation coefficient, r.
[12]:
ds_era5_regrid_clim = ds_era5_regrid.mean("time").persist()
ds_barra2_clim = ds_barra2.mean("time").persist()
[13]:
nrows = len(varlist)
fig, axs = plt.subplots(nrows,3, figsize=((10,4*nrows)),subplot_kw={'projection': ccrs.PlateCarree(central_longitude=180)})
# Let's define the colour range for easier comparison
vminmax = {
'tas': (270,310),
'ta500': (240,270),
'uas': (-10,10),
'ua500': (-25,25),
'vas': (-10,10),
'va500': (-5,5),
'omega500': (-0.5,0.5),
'huss': (None, None),
'hus500': (None, None),
'ps': (75000,101000),
'psl': (97000,102000),
'prw': (10,60),
'pr': (0,5e-4),
'clt': (0,100),
'rsdt': (320,500),
'rsds': (150,400),
'rsut': (50,210),
'rlus': (300,520),
'rlds': (300,420),
'rlut': (150,300),
'zg500': (5200, 5800),
}
# Plot all variable comparisons
for i, var in enumerate(varlist):
r = xr.corr(
ds_era5_regrid_clim[barra2era_map[var]],
ds_barra2_clim[var]
).values
ds_era5_regrid_clim[barra2era_map[var]].plot.pcolormesh(ax=axs[i,0], vmin=vminmax[var][0], vmax=vminmax[var][1], transform=ccrs.PlateCarree(), cbar_kwargs=dict(shrink=0.4))
ds_barra2_clim[var].plot.pcolormesh(ax=axs[i,1], vmin=vminmax[var][0], vmax=vminmax[var][1], transform=ccrs.PlateCarree(), cbar_kwargs=dict(shrink=0.4))
(ds_era5_regrid_clim[barra2era_map[var]]-ds_barra2_clim[var]).plot.pcolormesh(ax=axs[i,2], robust=True, transform=ccrs.PlateCarree(), cbar_kwargs=dict(shrink=0.4))
axs[i,0].set_title(f"ERA5 - {var}")
axs[i,1].set_title(f"BARRA2 - {var}")
axs[i,2].set_title(f"ERA5 minus BARRA-R2 (r={r:.2f})")

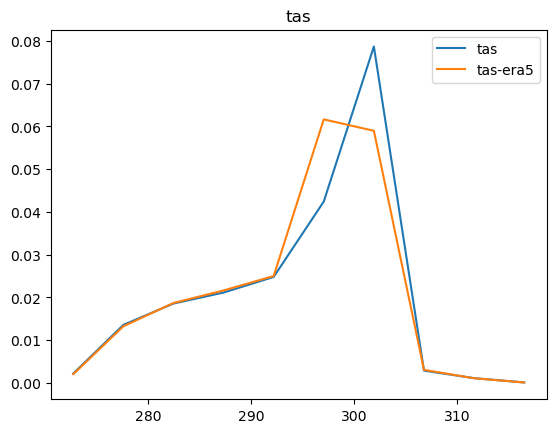
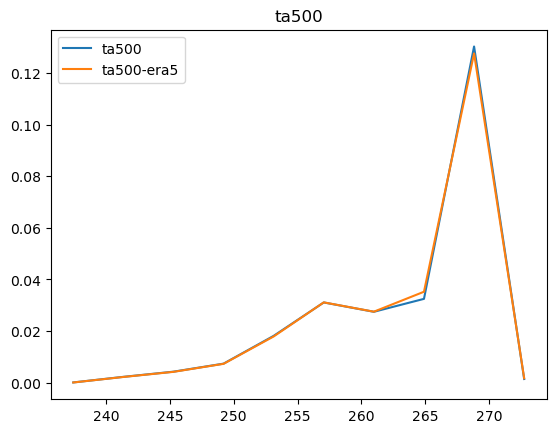
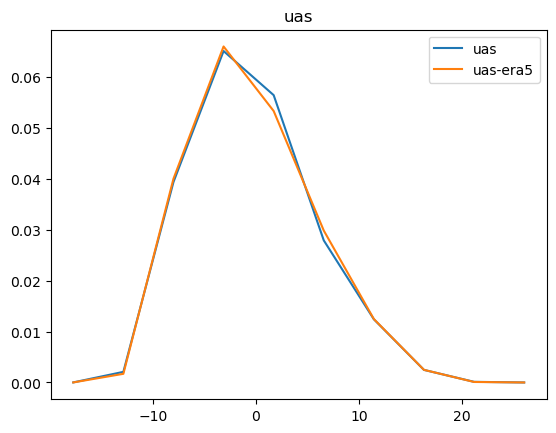
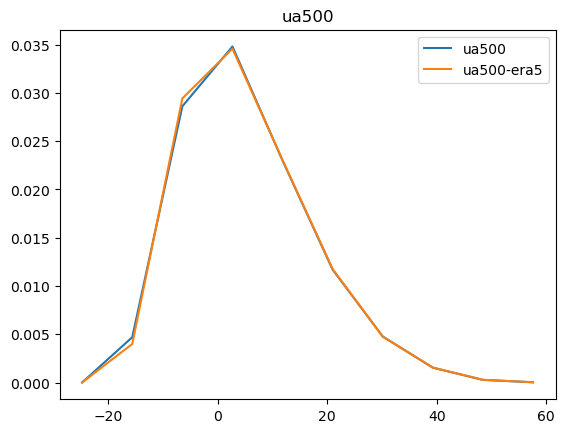
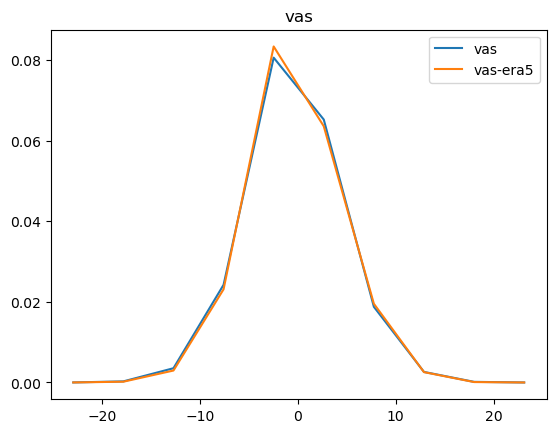
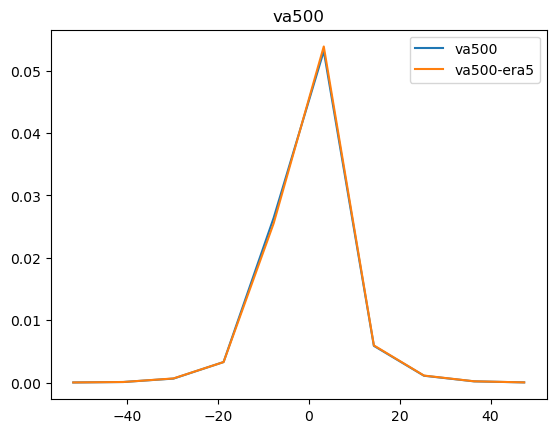
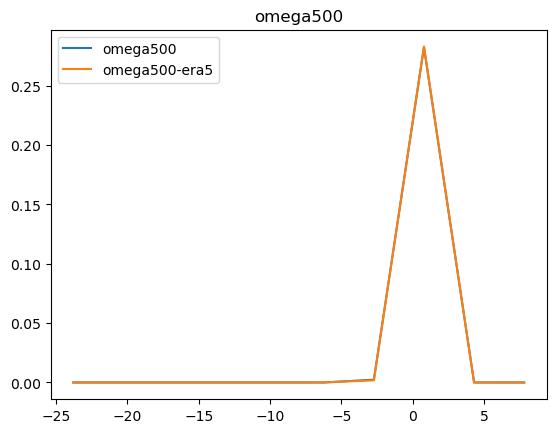
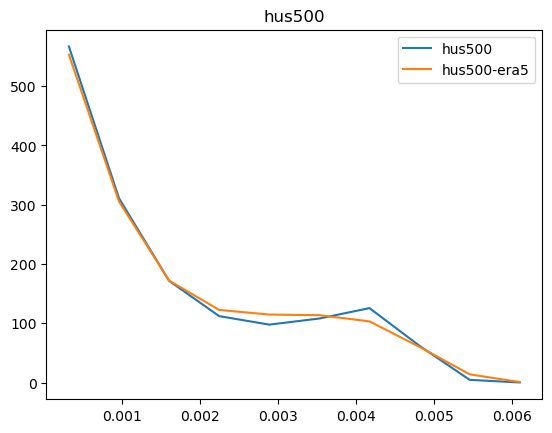
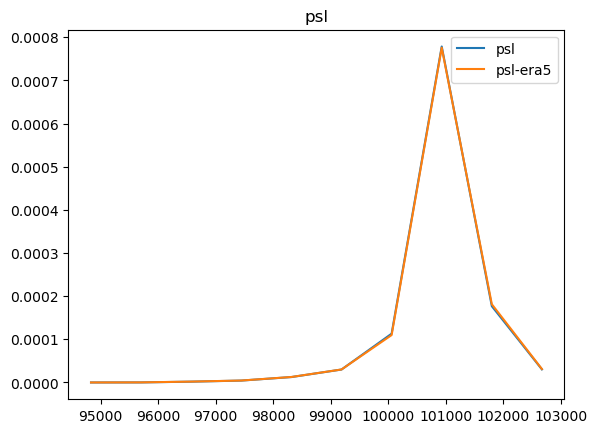
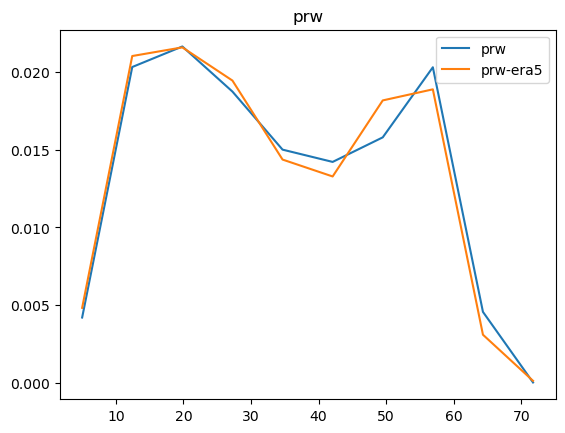
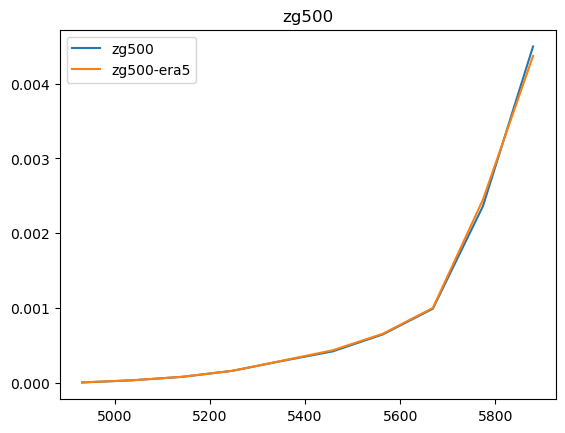
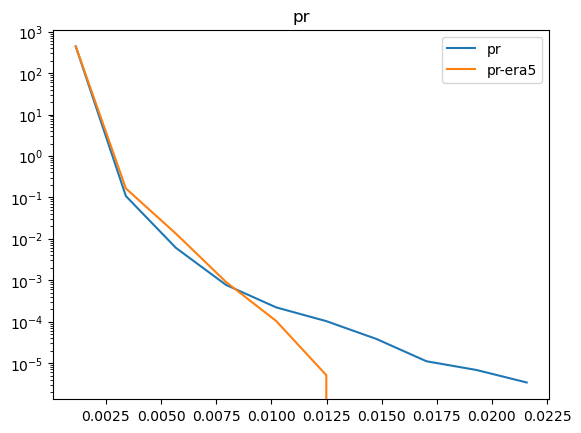
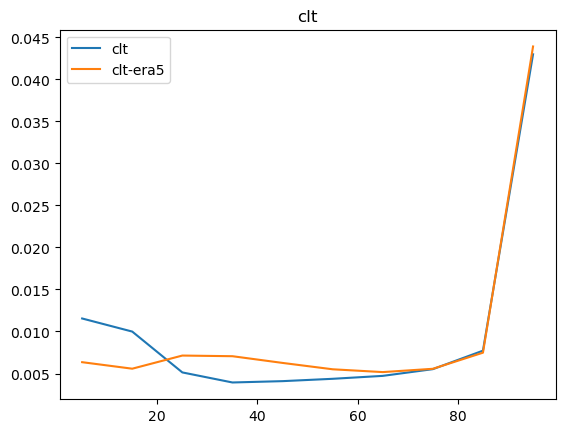
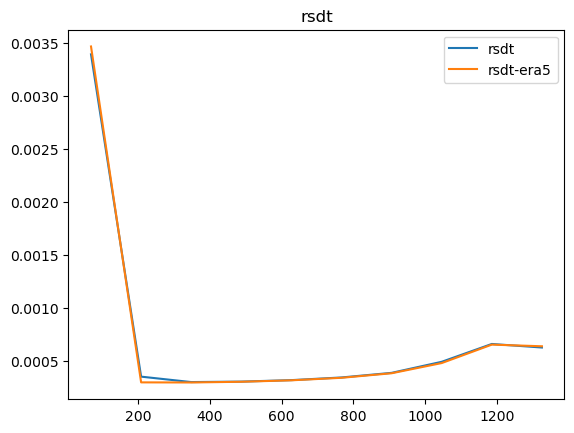
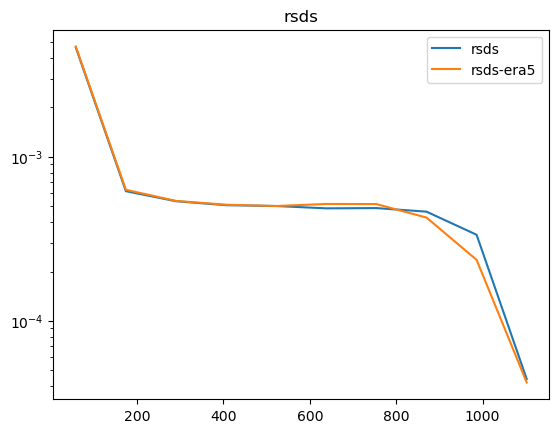
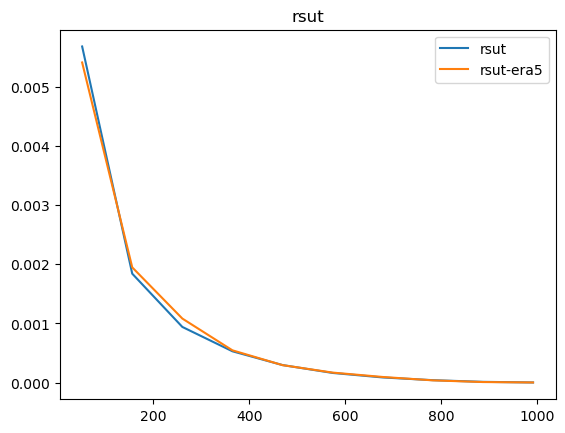
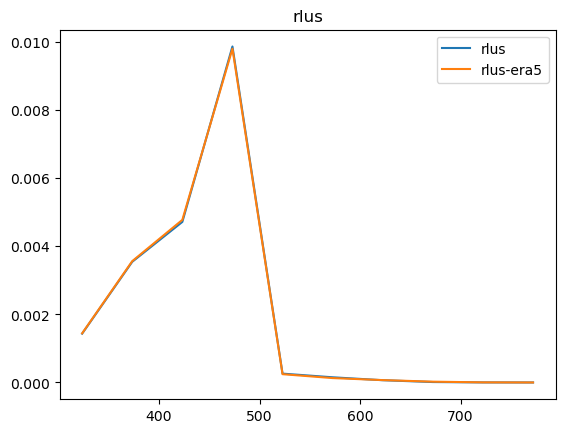
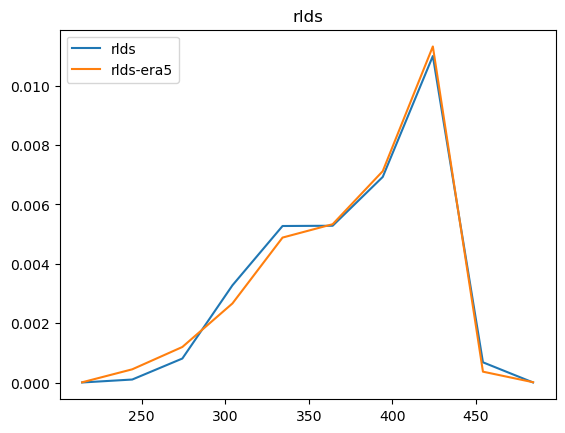
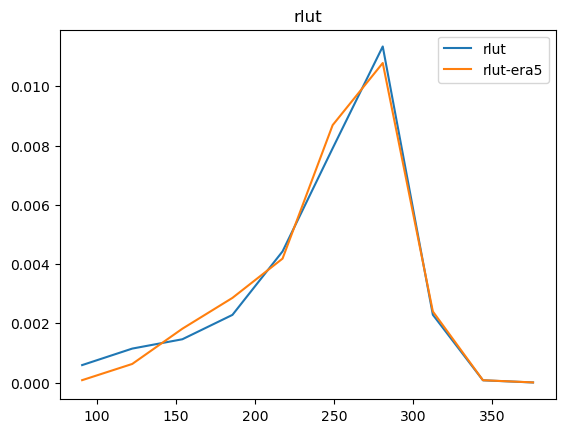
Now that we have compared the mean maps, lets look at the histograms. For the histograms we do not need the mean values, we can consider the histogram over all hourly values.
For some histograms a log axis is more useful.
[14]:
def moving_average(a, n=2):
ret = np.cumsum(a, dtype=float)
ret[n:] = ret[n:] - ret[:-n]
return ret[n - 1:] / n
log_xaxis = []
log_yaxis = ['ps', 'pr', 'rsds']
for var in varlist:
n_barra2, bins_barra2 = np.histogram(ds_barra2[var], density=True)
n_era5, bins_era5 = np.histogram(ds_era5_regrid[barra2era_map[var]], bins=bins_barra2, density=True)
plt.figure()
plt.plot(moving_average(bins_barra2), n_barra2, label=var)
plt.plot(moving_average(bins_era5), n_era5, label=f"{var}-era5")
plt.legend()
plt.title(var)
if var in log_xaxis:
plt.xscale('log')
else:
plt.xscale('linear')
if var in log_yaxis:
plt.yscale('log')
else:
plt.yscale('linear')
2025-10-10 15:50:16,929 - distributed.worker.memory - WARNING - Worker is at 80% memory usage. Pausing worker. Process memory: 8.05 GiB -- Worker memory limit: 10.05 GiB
2025-10-10 15:50:17,830 - distributed.worker.memory - WARNING - Worker is at 74% memory usage. Resuming worker. Process memory: 7.46 GiB -- Worker memory limit: 10.05 GiB
2025-10-10 15:50:45,243 - distributed.worker.memory - WARNING - Worker is at 80% memory usage. Pausing worker. Process memory: 8.05 GiB -- Worker memory limit: 10.05 GiB
2025-10-10 15:50:45,903 - distributed.worker.memory - WARNING - Worker is at 58% memory usage. Resuming worker. Process memory: 5.88 GiB -- Worker memory limit: 10.05 GiB
2025-10-10 15:51:03,700 - distributed.worker.memory - WARNING - Worker is at 80% memory usage. Pausing worker. Process memory: 8.05 GiB -- Worker memory limit: 10.05 GiB
2025-10-10 15:51:04,475 - distributed.worker.memory - WARNING - Worker is at 75% memory usage. Resuming worker. Process memory: 7.62 GiB -- Worker memory limit: 10.05 GiB
2025-10-10 15:51:44,301 - distributed.worker.memory - WARNING - Worker is at 80% memory usage. Pausing worker. Process memory: 8.05 GiB -- Worker memory limit: 10.05 GiB
2025-10-10 15:51:44,842 - distributed.worker.memory - WARNING - Worker is at 62% memory usage. Resuming worker. Process memory: 6.24 GiB -- Worker memory limit: 10.05 GiB
2025-10-10 15:52:09,029 - distributed.worker.memory - WARNING - Worker is at 80% memory usage. Pausing worker. Process memory: 8.05 GiB -- Worker memory limit: 10.05 GiB
2025-10-10 15:52:09,816 - distributed.worker.memory - WARNING - Worker is at 75% memory usage. Resuming worker. Process memory: 7.56 GiB -- Worker memory limit: 10.05 GiB
2025-10-10 15:52:42,598 - distributed.worker.memory - WARNING - Worker is at 80% memory usage. Pausing worker. Process memory: 8.06 GiB -- Worker memory limit: 10.05 GiB
2025-10-10 15:52:43,737 - distributed.worker.memory - WARNING - Worker is at 41% memory usage. Resuming worker. Process memory: 4.20 GiB -- Worker memory limit: 10.05 GiB
2025-10-10 15:53:02,145 - distributed.worker.memory - WARNING - Worker is at 80% memory usage. Pausing worker. Process memory: 8.06 GiB -- Worker memory limit: 10.05 GiB
2025-10-10 15:53:03,058 - distributed.worker.memory - WARNING - Worker is at 76% memory usage. Resuming worker. Process memory: 7.69 GiB -- Worker memory limit: 10.05 GiB
2025-10-10 15:53:44,726 - distributed.worker.memory - WARNING - Worker is at 80% memory usage. Pausing worker. Process memory: 8.05 GiB -- Worker memory limit: 10.05 GiB
2025-10-10 15:53:45,258 - distributed.worker.memory - WARNING - Worker is at 63% memory usage. Resuming worker. Process memory: 6.36 GiB -- Worker memory limit: 10.05 GiB
2025-10-10 15:54:08,432 - distributed.worker.memory - WARNING - Worker is at 80% memory usage. Pausing worker. Process memory: 8.06 GiB -- Worker memory limit: 10.05 GiB
2025-10-10 15:54:09,419 - distributed.worker.memory - WARNING - Worker is at 74% memory usage. Resuming worker. Process memory: 7.46 GiB -- Worker memory limit: 10.05 GiB
2025-10-10 15:54:37,570 - distributed.worker.memory - WARNING - Worker is at 80% memory usage. Pausing worker. Process memory: 8.06 GiB -- Worker memory limit: 10.05 GiB
2025-10-10 15:54:38,418 - distributed.worker.memory - WARNING - Worker is at 54% memory usage. Resuming worker. Process memory: 5.52 GiB -- Worker memory limit: 10.05 GiB
2025-10-10 15:54:57,858 - distributed.worker.memory - WARNING - Worker is at 80% memory usage. Pausing worker. Process memory: 8.06 GiB -- Worker memory limit: 10.05 GiB
2025-10-10 15:54:58,898 - distributed.worker.memory - WARNING - Worker is at 75% memory usage. Resuming worker. Process memory: 7.60 GiB -- Worker memory limit: 10.05 GiB
2025-10-10 15:55:41,249 - distributed.worker.memory - WARNING - Worker is at 80% memory usage. Pausing worker. Process memory: 8.06 GiB -- Worker memory limit: 10.05 GiB
2025-10-10 15:55:41,785 - distributed.worker.memory - WARNING - Worker is at 63% memory usage. Resuming worker. Process memory: 6.34 GiB -- Worker memory limit: 10.05 GiB
2025-10-10 15:56:00,575 - distributed.worker.memory - WARNING - Worker is at 80% memory usage. Pausing worker. Process memory: 8.06 GiB -- Worker memory limit: 10.05 GiB
2025-10-10 15:56:01,213 - distributed.worker.memory - WARNING - Worker is at 76% memory usage. Resuming worker. Process memory: 7.64 GiB -- Worker memory limit: 10.05 GiB
2025-10-10 15:56:44,130 - distributed.worker.memory - WARNING - Worker is at 80% memory usage. Pausing worker. Process memory: 8.06 GiB -- Worker memory limit: 10.05 GiB
2025-10-10 15:56:44,352 - distributed.worker.memory - WARNING - Worker is at 68% memory usage. Resuming worker. Process memory: 6.91 GiB -- Worker memory limit: 10.05 GiB
2025-10-10 15:57:05,271 - distributed.worker.memory - WARNING - Worker is at 80% memory usage. Pausing worker. Process memory: 8.06 GiB -- Worker memory limit: 10.05 GiB
2025-10-10 15:57:06,318 - distributed.worker.memory - WARNING - Worker is at 75% memory usage. Resuming worker. Process memory: 7.62 GiB -- Worker memory limit: 10.05 GiB
2025-10-10 15:57:48,547 - distributed.worker.memory - WARNING - Worker is at 80% memory usage. Pausing worker. Process memory: 8.05 GiB -- Worker memory limit: 10.05 GiB
2025-10-10 15:57:49,085 - distributed.worker.memory - WARNING - Worker is at 63% memory usage. Resuming worker. Process memory: 6.42 GiB -- Worker memory limit: 10.05 GiB
2025-10-10 15:58:08,032 - distributed.worker.memory - WARNING - Worker is at 80% memory usage. Pausing worker. Process memory: 8.06 GiB -- Worker memory limit: 10.05 GiB
2025-10-10 15:58:08,994 - distributed.worker.memory - WARNING - Worker is at 74% memory usage. Resuming worker. Process memory: 7.50 GiB -- Worker memory limit: 10.05 GiB
2025-10-10 15:58:40,139 - distributed.worker.memory - WARNING - Worker is at 80% memory usage. Pausing worker. Process memory: 8.07 GiB -- Worker memory limit: 10.05 GiB
2025-10-10 15:58:41,342 - distributed.worker.memory - WARNING - Worker is at 41% memory usage. Resuming worker. Process memory: 4.20 GiB -- Worker memory limit: 10.05 GiB
2025-10-10 15:59:00,131 - distributed.worker.memory - WARNING - Worker is at 80% memory usage. Pausing worker. Process memory: 8.05 GiB -- Worker memory limit: 10.05 GiB
2025-10-10 15:59:01,210 - distributed.worker.memory - WARNING - Worker is at 75% memory usage. Resuming worker. Process memory: 7.54 GiB -- Worker memory limit: 10.05 GiB
2025-10-10 15:59:30,522 - distributed.worker.memory - WARNING - Worker is at 80% memory usage. Pausing worker. Process memory: 8.08 GiB -- Worker memory limit: 10.05 GiB
2025-10-10 15:59:31,612 - distributed.worker.memory - WARNING - Worker is at 50% memory usage. Resuming worker. Process memory: 5.06 GiB -- Worker memory limit: 10.05 GiB
2025-10-10 15:59:50,670 - distributed.worker.memory - WARNING - Worker is at 80% memory usage. Pausing worker. Process memory: 8.05 GiB -- Worker memory limit: 10.05 GiB
2025-10-10 15:59:51,454 - distributed.worker.memory - WARNING - Worker is at 75% memory usage. Resuming worker. Process memory: 7.63 GiB -- Worker memory limit: 10.05 GiB
2025-10-10 16:00:28,765 - distributed.worker.memory - WARNING - Worker is at 80% memory usage. Pausing worker. Process memory: 8.06 GiB -- Worker memory limit: 10.05 GiB
2025-10-10 16:00:29,334 - distributed.worker.memory - WARNING - Worker is at 62% memory usage. Resuming worker. Process memory: 6.31 GiB -- Worker memory limit: 10.05 GiB
2025-10-10 16:00:51,016 - distributed.worker.memory - WARNING - Worker is at 80% memory usage. Pausing worker. Process memory: 8.06 GiB -- Worker memory limit: 10.05 GiB
2025-10-10 16:00:52,574 - distributed.worker.memory - WARNING - Worker is at 72% memory usage. Resuming worker. Process memory: 7.26 GiB -- Worker memory limit: 10.05 GiB
2025-10-10 16:01:22,516 - distributed.worker.memory - WARNING - Worker is at 80% memory usage. Pausing worker. Process memory: 8.06 GiB -- Worker memory limit: 10.05 GiB
2025-10-10 16:01:23,439 - distributed.worker.memory - WARNING - Worker is at 70% memory usage. Resuming worker. Process memory: 7.08 GiB -- Worker memory limit: 10.05 GiB
2025-10-10 16:01:43,520 - distributed.worker.memory - WARNING - Worker is at 80% memory usage. Pausing worker. Process memory: 8.05 GiB -- Worker memory limit: 10.05 GiB
2025-10-10 16:01:45,106 - distributed.worker.memory - WARNING - Worker is at 73% memory usage. Resuming worker. Process memory: 7.38 GiB -- Worker memory limit: 10.05 GiB
2025-10-10 16:02:13,184 - distributed.worker.memory - WARNING - Worker is at 80% memory usage. Pausing worker. Process memory: 8.08 GiB -- Worker memory limit: 10.05 GiB
2025-10-10 16:02:13,998 - distributed.worker.memory - WARNING - Worker is at 65% memory usage. Resuming worker. Process memory: 6.63 GiB -- Worker memory limit: 10.05 GiB
2025-10-10 16:02:33,032 - distributed.worker.memory - WARNING - Worker is at 80% memory usage. Pausing worker. Process memory: 8.07 GiB -- Worker memory limit: 10.05 GiB
2025-10-10 16:02:35,306 - distributed.worker.memory - WARNING - Worker is at 72% memory usage. Resuming worker. Process memory: 7.25 GiB -- Worker memory limit: 10.05 GiB
2025-10-10 16:03:01,809 - distributed.worker.memory - WARNING - Worker is at 80% memory usage. Pausing worker. Process memory: 8.07 GiB -- Worker memory limit: 10.05 GiB
2025-10-10 16:03:02,630 - distributed.worker.memory - WARNING - Worker is at 69% memory usage. Resuming worker. Process memory: 6.99 GiB -- Worker memory limit: 10.05 GiB
2025-10-10 16:03:24,937 - distributed.worker.memory - WARNING - Worker is at 80% memory usage. Pausing worker. Process memory: 8.07 GiB -- Worker memory limit: 10.05 GiB
2025-10-10 16:03:27,017 - distributed.worker.memory - WARNING - Worker is at 68% memory usage. Resuming worker. Process memory: 6.93 GiB -- Worker memory limit: 10.05 GiB
2025-10-10 16:03:54,105 - distributed.worker.memory - WARNING - Worker is at 80% memory usage. Pausing worker. Process memory: 8.06 GiB -- Worker memory limit: 10.05 GiB
2025-10-10 16:03:55,012 - distributed.worker.memory - WARNING - Worker is at 65% memory usage. Resuming worker. Process memory: 6.61 GiB -- Worker memory limit: 10.05 GiB
2025-10-10 16:04:14,689 - distributed.worker.memory - WARNING - Worker is at 80% memory usage. Pausing worker. Process memory: 8.06 GiB -- Worker memory limit: 10.05 GiB
2025-10-10 16:04:16,255 - distributed.worker.memory - WARNING - Worker is at 70% memory usage. Resuming worker. Process memory: 7.08 GiB -- Worker memory limit: 10.05 GiB
2025-10-10 16:04:49,276 - distributed.worker.memory - WARNING - Worker is at 80% memory usage. Pausing worker. Process memory: 8.07 GiB -- Worker memory limit: 10.05 GiB
2025-10-10 16:04:50,468 - distributed.worker.memory - WARNING - Worker is at 67% memory usage. Resuming worker. Process memory: 6.74 GiB -- Worker memory limit: 10.05 GiB
2025-10-10 16:05:09,974 - distributed.worker.memory - WARNING - Worker is at 80% memory usage. Pausing worker. Process memory: 8.06 GiB -- Worker memory limit: 10.05 GiB
2025-10-10 16:05:11,952 - distributed.worker.memory - WARNING - Worker is at 72% memory usage. Resuming worker. Process memory: 7.31 GiB -- Worker memory limit: 10.05 GiB
2025-10-10 16:05:46,296 - distributed.worker.memory - WARNING - Worker is at 80% memory usage. Pausing worker. Process memory: 8.06 GiB -- Worker memory limit: 10.05 GiB
2025-10-10 16:05:47,066 - distributed.worker.memory - WARNING - Worker is at 41% memory usage. Resuming worker. Process memory: 4.20 GiB -- Worker memory limit: 10.05 GiB
2025-10-10 16:06:07,540 - distributed.worker.memory - WARNING - Worker is at 80% memory usage. Pausing worker. Process memory: 8.05 GiB -- Worker memory limit: 10.05 GiB
2025-10-10 16:06:09,478 - distributed.worker.memory - WARNING - Worker is at 72% memory usage. Resuming worker. Process memory: 7.27 GiB -- Worker memory limit: 10.05 GiB
2025-10-10 16:06:37,633 - distributed.worker.memory - WARNING - Worker is at 80% memory usage. Pausing worker. Process memory: 8.06 GiB -- Worker memory limit: 10.05 GiB
2025-10-10 16:06:38,259 - distributed.worker.memory - WARNING - Worker is at 59% memory usage. Resuming worker. Process memory: 6.01 GiB -- Worker memory limit: 10.05 GiB
2025-10-10 16:06:58,819 - distributed.worker.memory - WARNING - Worker is at 80% memory usage. Pausing worker. Process memory: 8.07 GiB -- Worker memory limit: 10.05 GiB
2025-10-10 16:07:00,860 - distributed.worker.memory - WARNING - Worker is at 72% memory usage. Resuming worker. Process memory: 7.32 GiB -- Worker memory limit: 10.05 GiB
2025-10-10 16:07:30,755 - distributed.worker.memory - WARNING - Worker is at 80% memory usage. Pausing worker. Process memory: 8.04 GiB -- Worker memory limit: 10.05 GiB
2025-10-10 16:07:31,450 - distributed.worker.memory - WARNING - Worker is at 62% memory usage. Resuming worker. Process memory: 6.24 GiB -- Worker memory limit: 10.05 GiB
Summary#
This concludes the introduction on using BARRA-R2 and ERA5 data in PyEarthTools. We have covered:
the loading of BARRA-R2 and ERA5 data,
combining hourly instantaneous and hourly averaged variables into a single dataset,
regridding ERA5 to BARRA-R2 resolution,
and plotting of mean maps and histograms of BARRA-R2 and ERA5.
The steps taken here to match BARRA-R2 to ERA5 will be useful when designing pipelines for training ML models.
[ ]: